一
2024年4月,北京车展。
有人戏称,在传统意义上的车模缺位后,所有目光都聚焦在两个人身上:一个红男,一个绿男。

这两位确实一时里风头无两,但有趣的事是,在我个人的社交圈里,评价是不大一样的。
比如我这位朋友在一个行业大群里,颇有一些阴阳怪气地发表了他的看法:
这遭来了红男同样有点阴阳怪气的回怼。
双方的个中意味,看客们大约都是能琢磨出来的。
二
前儿和几个朋友聊天时开玩笑说道,雷军可谓是行业毒瘤。
小米作为一个非常抠门的主是名声在外的,早年刚开始做手机时,不进行任何广告投放。至于软文,间或会买几篇,但价格也是出了名的低。以至于当初小米公关徐洁云(也就是上面照片里雷军左侧的那位)几乎靠卖人情在那里铺稿子的做派广为人知。
这对通讯行业的媒体而言,并不是什么好事。如果只是小米一家这么干也就罢了,问题是小米崛起神速,这是会带坏整个行业的,:)
现在,小米又杀入了汽车行业。汽车领域的媒体过去预算极其丰厚。我甚至听说过某汽车媒体人因厂商在活动时未能给其安排公务舱扭头就走的段子。但特斯拉杀入已经算是破坏行业规则了,抠门之王小米再冲进来,让大家情何以堪。
中旬的上海车展,雷军现身劳斯莱斯展台,“他掏出自己的小米手机,对着展台上的劳斯莱斯汽车就是一顿拍摄。从外观到内饰,从细节到整体,他似乎想要用镜头记录下这辆豪华车的每一个瞬间。”——有媒体如是报道。
啊呀,雷老板这么搞法,岂非要大大压缩汽车行业咨询公司的收入。
三
前阵子有人问我,怎么看待su7的成功呢?
我的回答是:现在说成功,言之过早了。
营销造势确实是声势浩大,但也确实是还没法评估出“成功”二字。所谓大定完成多少多少,毕竟还不知道是不是包括2B(也就是经销商),如果包括,那么2B和2C又各自占比多少呢?
毕竟有董妈妈当初直播销量几乎靠经销商撑起的案例在前头。
雷军在北京车展上宣布,小米汽车已经交付5700台。这个开局不错,但当然还是要努力。小米是3月28日晚间正式宣布价格的,次交易日跳空开盘然后下滑,一番整理后,到今日(4月26日)跳空上扬收盘17.36,走势如下(其实资本市场可以用不看好也不看坏来形容):
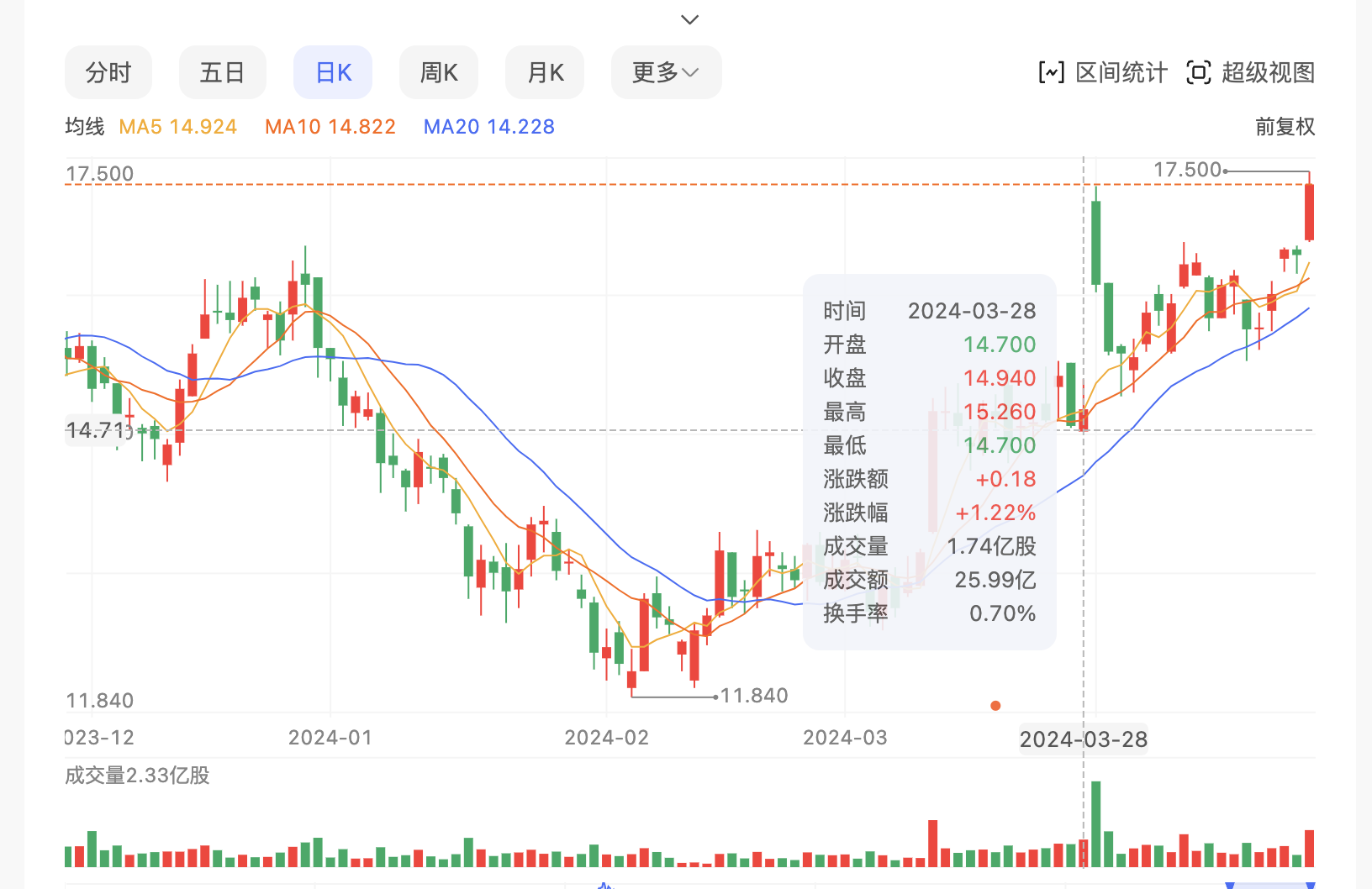
所以在宣布车价后,雷老板亲自出击,继续擂鼓冲锋,不敢有一丝懈怠。行业毒瘤的特色又出现了,搞得同行的老大们又得提枪上马做网红了。蔚小理倒也罢了,本来也是这么出来的,但还有更多的汽车公司老大们——尤其是传统车商们——着实头疼。
这就是雷军是个行动的广告牌的由来。做网红不是目的,而是为了后面的小米汽车。
至于是不是招人烦,那就见仁见智了。
四
回过头来看红男,著名的红衣教主或红衣大炮周鸿祎。
与雷军早期不大抛头露面所不同的是,周鸿祎打从有社会化媒体社交网络以来,就一直喜欢冲锋在前。可以这么说,雷军是通过学习做了网红,周鸿祎是做了网红然后学习成为更大的网红——一个是后天的,一个是先天的。
之所以被称为大炮,是因为他和所谓BAT三大互联网顶流公司都干过仗。
最早的是3A大战,周鸿祎离开被阿里收购的雅虎中国后,杀了一记回马枪,也就是所谓“流氓软件教父幡然醒悟”的故事。至于到底是良心发现,还是赚钱需要,这种心里的盘算,就不晓得了。反正当初把阿里弄得火冒三丈,公开宣布阿里系旗下所有业务单位,永不和周鸿祎的公司有商业合作往来。当然,这句誓言后来是打破了的。
然后就是震惊中国网络产业和网络用户的3Q大战。这里我有一个事实要指出,这场大战其实是腾讯开的第一枪,也就是率先依靠QQ静默安装腾讯家的安全软件。这引起了周鸿祎的强势反弹,大战的结果也引起了腾讯的反思,召开了十场诊断腾讯的闭门会。这场网络口水仗意义深远,深刻影响了行业格局,绝不仅仅是什么公关层面上的撕逼。
再然后就是3B大战,随着搜狗后来的入局,又称3SB大战。与3A大战一样,也是周鸿祎主动出击,想依靠市占第一的360浏览器,抢夺搜索市场份额。但这场战役动静其实不大,不仅没法和3Q相比,和3A也不是一个量级的。而且结果也一般,360搜索获得了一定的份额,但对百度的市场地位,并没有动摇多少。
这三场战役,周鸿祎都冲锋在前,尤其是到了3Q和3B之时,微博已然普及,他不断利用社会化媒体引导舆情舆论,大杀四方。相比之下,无论是马云还是马化腾抑或李彦宏,都不曾这样玩过。在我看来,周鸿祎确实天生就擅长成为一名网红。
后来,周鸿祎和雷军在社交媒体上还有过一轮口水撕逼,但背后依然存在一个原因:周鸿祎当时正在做手机,至少是自有品牌的手机。
可见,做网红也都是有目的的,网红本身,只是商业竞争的武器。
五
但在这次车展上,周鸿祎又成了一个网红,就有些难以理解了。因为很显然,当下周氏尚未有汽车业务。
周鸿祎前一阵子,在AI圈很是卖力,360智脑是他的“自研认知通用大模型”,就在这个月,周氏还宣布马上就要推出360AI办公套件,计划一年搞它营收一个亿。
这大概就是他所谓的“要推广人工智能,这是道”的由来。毕竟,现在一提起新能源汽车,都会或多或少扯上点“人工智能”。
换而言之,周鸿祎不放弃任何一个有可能和AI有关的流量场合,努力吆喝,靠网红定位,为自己的人工智能业务带上一波流量。
但实话实说,当年周鸿祎用网红干的几大战役,成有成的原因:3A大战,网民苦流氓软件久矣。3Q大战,产业苦“有什么是腾讯不做的么”久矣。但到了3B大战,周雷互撕,热闹归热闹,但缺少那份久矣的大潮,网红的作用,貌似有限。
再加上这些年,360全家桶的口碑,着实也就。。。那么一回事吧。
很大程度上,周鸿祎一直需要一个标靶自己来作为一股反抗力量出现,如有,则网红成;如无,则泯然众人。
却也不知,在LLM百舸竞渡的今天,网红吆喝诚然有用,但到底权重几何呢?
—— 首发 扯氮集 ——